Upgrade from v1.0.2 to v1.0.3
General information
The Harvester GUI Dashboard page should have an upgrade button to perform an upgrade. For more details please refer to start an upgrade.
For the air-gap env upgrade, please refer to prepare an air-gapped upgrade.
Known issues
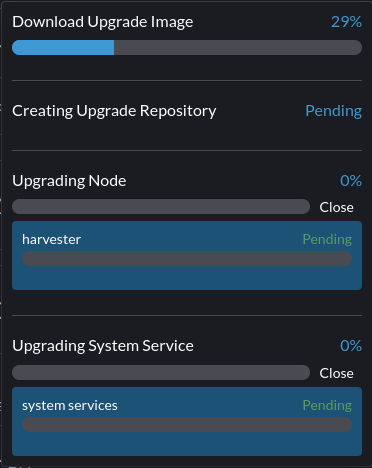
1. Fail to download the upgrade image
Description
Downloading the upgrade image can't be complete or fails with an error.
Related issues
Workaround
Delete the current upgrade and start over. Please see "Start over an upgrade".
2. An upgrade is stuck, a node is in "Pre-drained" state (case 1)
Description
Users might see a node is stuck at the Pre-drained state for a while (> 30 minutes).
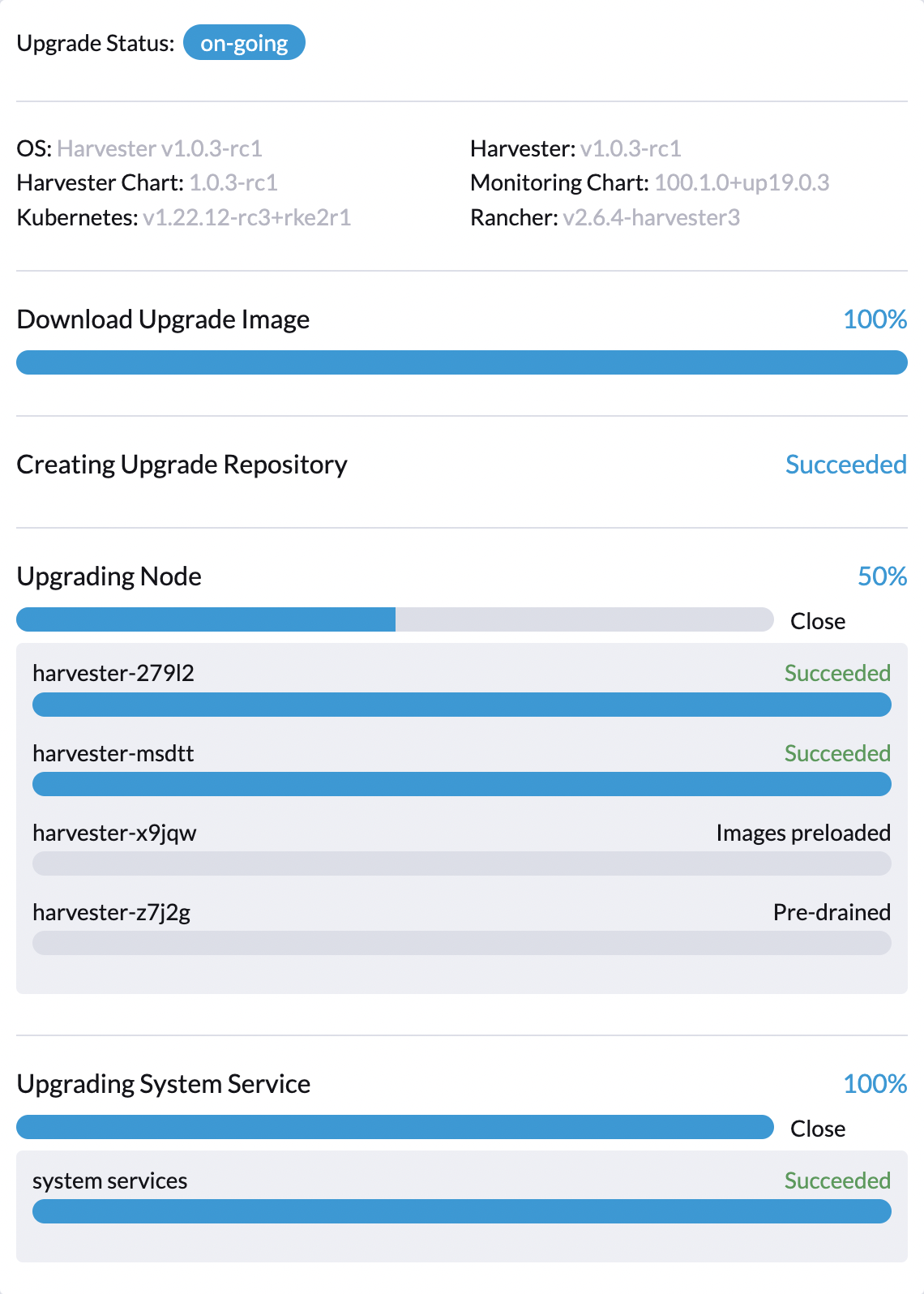
This might be caused by instance-manager-r-* pod on node harvester-z7j2g can’t be drained. To verify the above case:
- Check rancher server logs:Example output:
kubectl logs deployment/rancher -n cattle-systemerror when evicting pods/"instance-manager-r-10dd59c4" -n "longhorn-system" (will retry after 5s): Cannot evict pod as it would violate the pod's disruption budget.
evicting pod longhorn-system/instance-manager-r-10dd59c4
error when evicting pods/"instance-manager-r-10dd59c4" -n "longhorn-system" (will retry after 5s): Cannot evict pod as it would violate the pod's disruption budget.
evicting pod longhorn-system/instance-manager-r-10dd59c4
error when evicting pods/"instance-manager-r-10dd59c4" -n "longhorn-system" (will retry after 5s): Cannot evict pod as it would violate the pod's disruption budget.
evicting pod longhorn-system/instance-manager-r-10dd59c4
error when evicting pods/"instance-manager-r-10dd59c4" -n "longhorn-system" (will retry after 5s): Cannot evict pod as it would violate the pod's disruption budget. - Verify the pod
longhorn-system/instance-manager-r-10dd59c4is on the stuck node:Example output:kubectl get pod instance-manager-r-10dd59c4 -n longhorn-system -o=jsonpath='{.spec.nodeName}'harvester-z7j2g - Check degraded volumes:Example output:
kubectl get volumes -n longhorn-systemHere we can see volumeNAME STATE ROBUSTNESS SCHEDULED SIZE NODE AGE
pvc-08c34593-8225-4be6-9899-10a978df6ea1 attached healthy True 10485760 harvester-279l2 3d13h
pvc-526600f5-bde2-4244-bb8e-7910385cbaeb attached healthy True 21474836480 harvester-x9jqw 3d1h
pvc-7b3fc2c3-30eb-48b8-8a98-11913f8314c2 attached healthy True 10737418240 harvester-x9jqw 3d
pvc-8065ed6c-a077-472c-920e-5fe9eacff96e attached healthy True 21474836480 harvester-x9jqw 3d
pvc-9a40e5b9-543a-4c90-aafd-ac78b05d7599 attached degraded True 10737418240 harvester-x9jqw 2d23h
pvc-9a6539b8-44e5-430e-9b24-ea8290cb13b7 attached healthy True 53687091200 harvester-x9jqw 3d13hpvc-9a40e5b9-543a-4c90-aafd-ac78b05d7599is degraded.
The user needs to check all degraded volumes one by one.
- Check degraded volume’s replica state:Example output:
kubectl get replicas -n longhorn-system --selector longhornvolume=pvc-9a40e5b9-543a-4c90-aafd-ac78b05d7599 -o json | jq '.items[] | {replica: .metadata.name, healthyAt: .spec.healthyAt, nodeID: .spec.nodeID, state: .status.currentState}'Here the only healthy replica is{
"replica": "pvc-9a40e5b9-543a-4c90-aafd-ac78b05d7599-r-15e31246",
"healthyAt": "2022-07-25T07:33:16Z",
"nodeID": "harvester-z7j2g",
"state": "running"
}
{
"replica": "pvc-9a40e5b9-543a-4c90-aafd-ac78b05d7599-r-22974d0f",
"healthyAt": "",
"nodeID": "harvester-279l2",
"state": "running"
}
{
"replica": "pvc-9a40e5b9-543a-4c90-aafd-ac78b05d7599-r-bc6f7fa5",
"healthyAt": "",
"nodeID": "harvester-x9jqw",
"state": "stopped"
}pvc-9a40e5b9-543a-4c90-aafd-ac78b05d7599-r-15e31246and it’s on nodeharvester-z7j2g. So we can confirm theinstance-manager-r-*pod resides on nodeharvester-z7j2gand avoids the drain.
Related issues
Workaround
We need to start the “Stopped” replica, from the previous example, the stopped replica’s name is pvc-9a40e5b9-543a-4c90-aafd-ac78b05d7599-r-bc6f7fa5.
- Check the Longhorn manager log, we should see a replica waiting for the backing image. First, we need to get the manager's name:Example output:
kubectl get pods -n longhorn-system --selector app=longhorn-manager --field-selector spec.nodeName=harvester-x9jqw
NAME READY STATUS RESTARTS AGE
longhorn-manager-zmfbw 1/1 Running 0 3d10h - Get pod log:Example output:
kubectl logs longhorn-manager-zmfbw -n longhorn-system | grep pvc-9a40e5b9-543a-4c90-aafd-ac78b05d7599-r-bc6f7fa5Here we can determine the replica is waiting for the backing image(...)
time="2022-07-28T04:35:34Z" level=debug msg="Prepare to create instance pvc-9a40e5b9-543a-4c90-aafd-ac78b05d7599-r-bc6f7fa5"
time="2022-07-28T04:35:34Z" level=debug msg="Replica pvc-9a40e5b9-543a-4c90-aafd-ac78b05d7599-r-bc6f7fa5 is waiting for backing image harvester-system-harvester-iso-n7bxh downloading file to node harvester-x9jqw disk 3830342d-c13d-4e55-ac74-99cad529e9d4, the current state is in-progress" controller=longhorn-replica dataPath= node=harvester-x9jqw nodeID=harvester-x9jqw ownerID=harvester-x9jqw replica=pvc-9a40e5b9-543a-4c90-aafd-ac78b05d7599-r-bc6f7fa5
time="2022-07-28T04:35:34Z" level=info msg="Event(v1.ObjectReference{Kind:\"Replica\", Namespace:\"longhorn-system\", Name:\"pvc-9a40e5b9-543a-4c90-aafd-ac78b05d7599-r-bc6f7fa5\", UID:\"c511630f-2fe2-4cf9-97a4-21bce73782b1\", APIVersion:\"longhorn.io/v1beta1\", ResourceVersion:\"632926\", FieldPath:\"\"}): type: 'Normal' reason: 'Start' Starts pvc-9a40e5b9-543a-4c90-aafd-ac78b05d7599-r-bc6f7fa5"harvester-system-harvester-iso-n7bxh. - Get the disk file map from the backing image:Example output:
kubectl describe backingimage harvester-system-harvester-iso-n7bxh -n longhorn-systemThe disk file with UUID(...)
Disk File Status Map:
3830342d-c13d-4e55-ac74-99cad529e9d4:
Last State Transition Time: 2022-07-25T08:30:34Z
Message:
Progress: 29
State: in-progress
3aa804e1-229d-4141-8816-1f6a7c6c3096:
Last State Transition Time: 2022-07-25T08:33:20Z
Message:
Progress: 100
State: ready
92726efa-bfb3-478e-8553-3206ad34ce70:
Last State Transition Time: 2022-07-28T04:31:49Z
Message:
Progress: 100
State: ready3830342d-c13d-4e55-ac74-99cad529e9d4has the statein-progress. - Next, we need to find backing-image-manager that contains this disk file:Example output:
kubectl get pod -n longhorn-system --selector=longhorn.io/disk-uuid=3830342d-c13d-4e55-ac74-99cad529e9d4NAME READY STATUS RESTARTS AGE
backing-image-manager-c00e-3830 1/1 Running 0 3d1h - Restart the backing-image-manager by deleting its pod:
kubectl delete pod -n longhorn-system backing-image-manager-c00e-3830
3. An upgrade is stuck, a node is in "Pre-drained" state (case 2)
Description
Users might see a node is stuck at the Pre-drained state for a while (> 30 minutes).
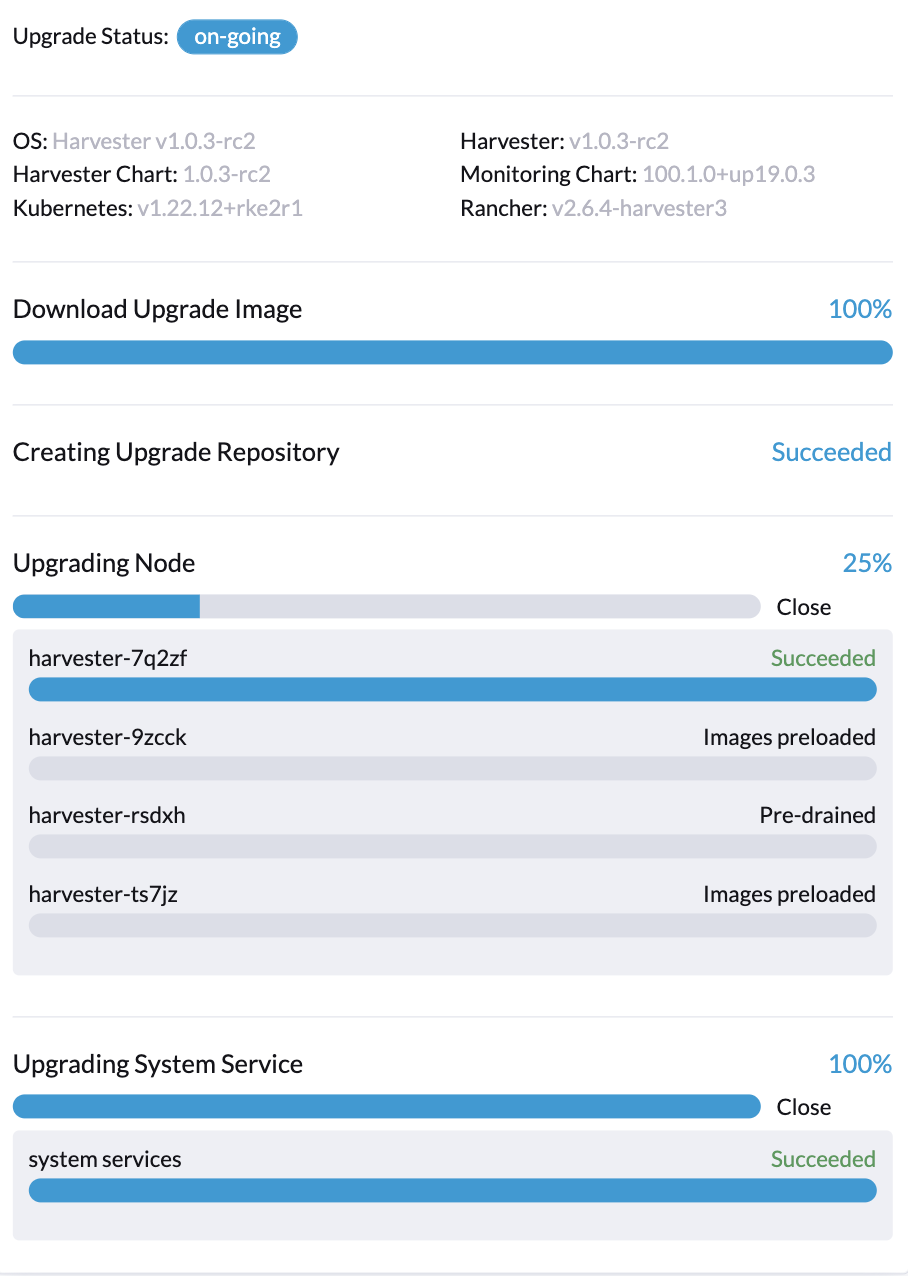
Here are some steps to verify this issue has happened:
Visit the Longhorn GUI:
https://{{VIP}}/k8s/clusters/local/api/v1/namespaces/longhorn-system/services/http:longhorn-frontend:80/proxy/#/volume(replace VIP with an appropriate value) and check degraded volumes. The degraded volume might contain a healthy replica only (with blue background) and the healthy replica resides on the "Pre-drained" node: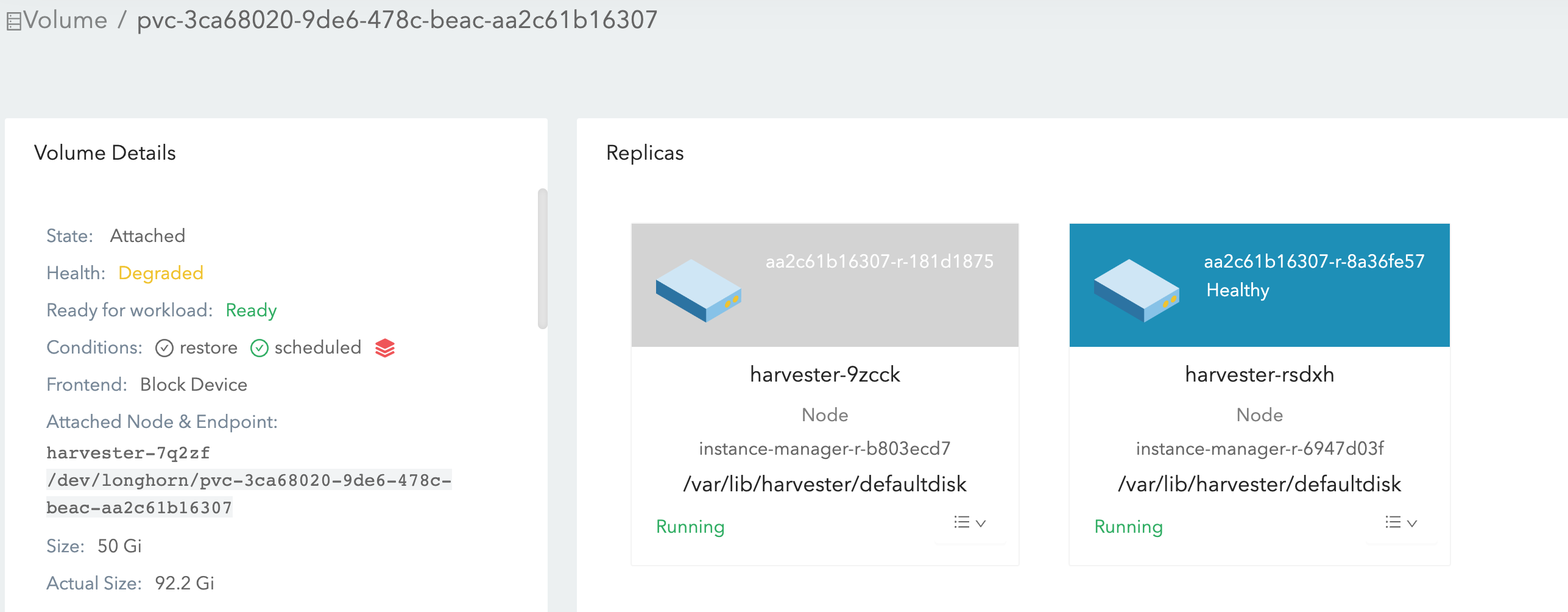
Hover the mouse to the red scheduled icon, the reason is
toomanysnapshots: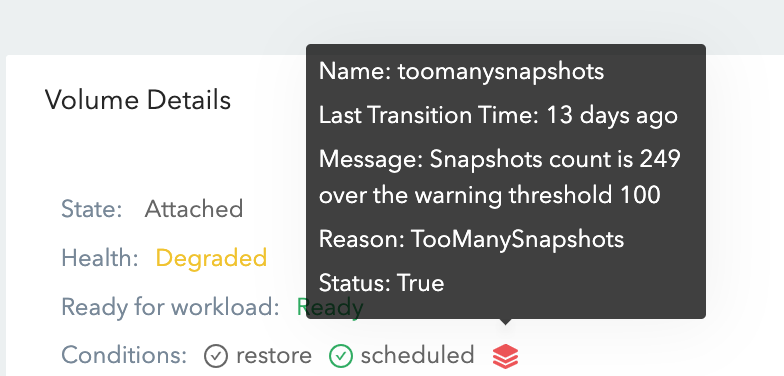
Related issues
Workaround
In the "Snapshots and Backup" panel, toggle the "Show System Hidden" switch and delete the latest system snapshot (which is just before the "Volume Head").
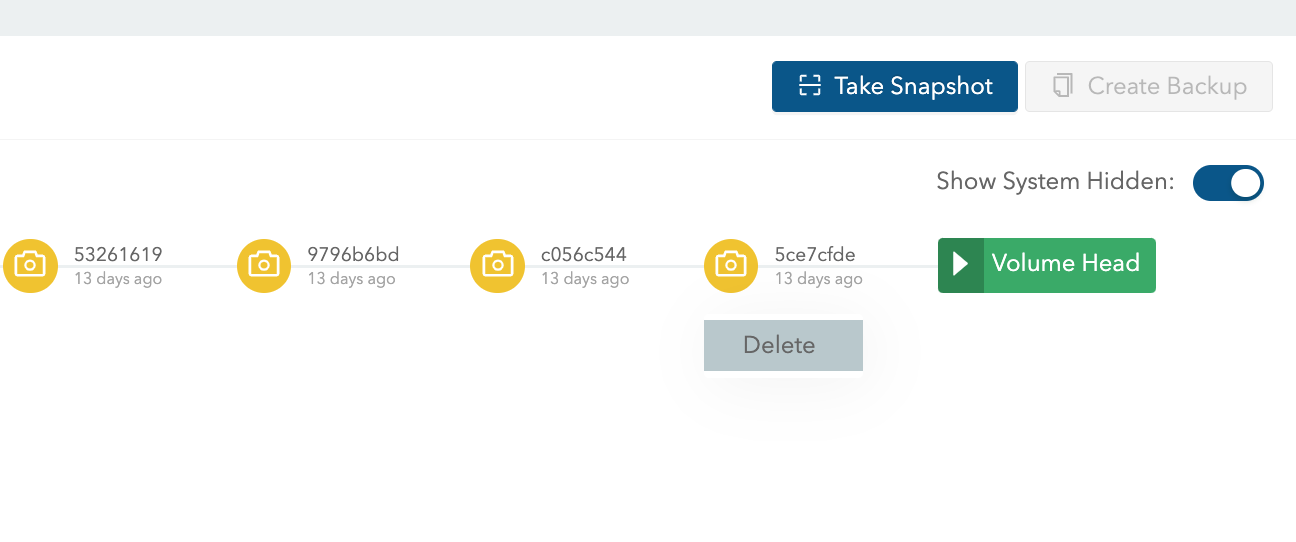
The volume will continue rebuilding to resume the upgrade.