Upgrade from v1.2.2/v1.3.0 to v1.3.1
General information
An Upgrade button appears on the Dashboard screen whenever a new Harvester version that you can upgrade to becomes available. For more information, see Start an upgrade.
For air-gapped environments, see Prepare an air-gapped upgrade.
Known issues
1. Cluster upgrade stuck after the first node is upgraded
To prevent this issue from occurring, label the local-kubeconfig secret before starting the upgrade process.
kubectl label secret local-kubeconfig -n fleet-local cluster.x-k8s.io/cluster-name=local
When upgrading a Harvester cluster from v1.2.2 or v1.3.0 to v1.3.1, the upgrade process becomes stuck after the first node is upgraded.
Example:
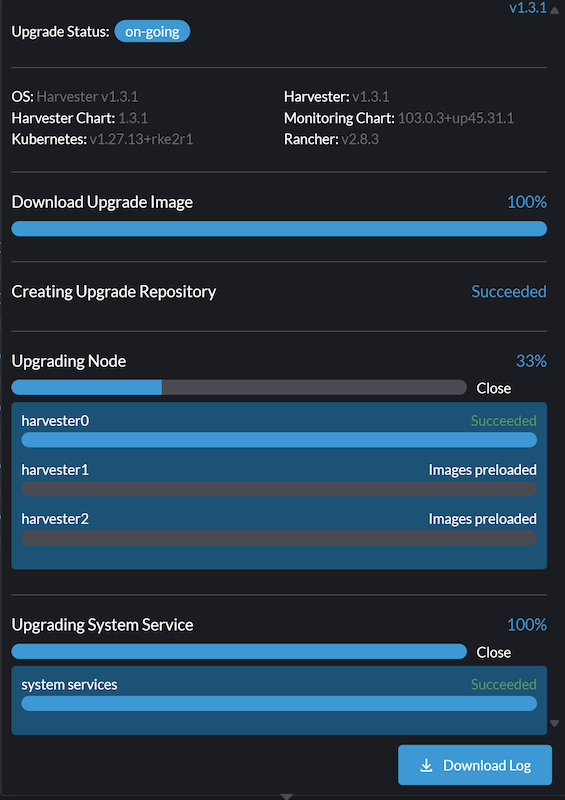
To resolve this issue, perform the following steps:
Identify the cluster status:
kubectl get clusters.provisioning.cattle.io local -n fleet-local -o yamlExample output:
...
- lastUpdateTime: "2024-06-18T23:37:39Z"
message: 'configuring bootstrap node(s) custom-9cb22ccf7984: waiting for kubelet
to update'
reason: Waiting
status: Unknown
type: Updated
- lastUpdateTime: "2024-06-18T23:37:39Z"
message: 'configuring bootstrap node(s) custom-9cb22ccf7984: waiting for kubelet
to update'
reason: Waiting
status: Unknown
type: ProvisionedIf the output includes the message
waiting for kubelet, continue to the next step.Check the
capi-controller-managerpod's logs:kubectl logs -n cattle-provisioning-capi-system deployment/capi-controller-managerIf the output is similar to the following example, the issue likely exists in the cluster.
2024-06-19T08:54:22.407423986Z W0619 08:54:22.407257 1 reflector.go:424] k8s.io/[email protected]/tools/cache/reflector.go:169: failed to list *v1.Node: Unauthorized
2024-06-19T08:54:22.407470069Z E0619 08:54:22.407283 1 reflector.go:140] k8s.io/[email protected]/tools/cache/reflector.go:169: Failed to watch *v1.Node: failed to list *v1.Node: Unauthorized
2024-06-19T08:55:05.153396619Z W0619 08:55:05.153190 1 reflector.go:424] k8s.io/[email protected]/tools/cache/reflector.go:169: failed to list *v1.Node: Unauthorized
2024-06-19T08:55:05.153438978Z E0619 08:55:05.153217 1 reflector.go:140] k8s.io/[email protected]/tools/cache/reflector.go:169: Failed to watch *v1.Node: failed to list *v1.Node: UnauthorizedApply the following workaround to resume the upgrade:
Kill and restart the
capi-controller-managerpod.Example:
kubectl rollout restart deployment/capi-controller-manager -n cattle-provisioning-capi-system
- Related issue:
2. Automatic image cleanup is not functioning
Because the published Harvester ISO contains an incomplete image list, automatic image cleanup cannot be performed during an upgrade from v1.2.2 to v1.3.1. This issue does not block the upgrade, and you can use this script to manually clean up container images after the upgrade is completed. For more information, see issue #6620.