Installation
The following sections contain tips to troubleshoot or get assistance with failed installations.
Logging into the Harvester Installer (a live OS)
Users can press the key combination CTRL + ALT + F2 to switch to another TTY and log in with the following credentials:
- User:
rancher - Password:
rancher
Meeting hardware requirements
- Check that your hardware meets the minimum requirements to complete installation.
Stuck in Loading images. This may take a few minutes...
Because the system doesn't have a default route, your installer may become "stuck" in this state. You can check your route status by executing the following command:
$ ip route
default via 10.10.0.10 dev mgmt-br proto dhcp <-- Does a default route exist?
10.10.0.0/24 dev mgmt-br proto kernel scope link src 10.10.0.15
Check that your DHCP server offers a default route option. Attaching content from /run/cos/target/rke2.log is helpful too.
For more information, see DHCP Server Configuration.
Modifying cluster token on agent nodes
When an agent node fails to join the cluster, it can be related to the cluster token not being identical to the server node token.
In order to confirm the issue, connect to your agent node (i.e. with SSH and check the rancherd service log with the following command:
$ sudo journalctl -b -u rancherd
If the cluster token setup in the agent node is not matching the server node token, you will find several entries of the following message:
msg="Bootstrapping Rancher (v2.7.5/v1.25.9+rke2r1)"
msg="failed to bootstrap system, will retry: generating plan: response 502: 502 Bad Gateway getting cacerts: <html>\r\n<head><title>502 Bad Gateway</title></head>\r\n<body>\r\n<center><h1>502 Bad Gateway</h1></center>\r\n<hr><center>nginx</center>\r\n</body>\r\n</html>\r\n"
Note that the Rancher version and IP address depend on your environment and might differ from the message above.
To fix the issue, you need to update the token value in the rancherd configuration file /etc/rancher/rancherd/config.yaml.
For example, if the cluster token setup in the server node is ThisIsTheCorrectOne, you will update the token value as follow:
token: 'ThisIsTheCorrectOne'
To ensure the change is persistent across reboots, update the token value of the OS configuration file /oem/90_custom.yaml:
name: Harvester Configuration
stages:
...
initramfs:
- commands:
- rm -f /etc/sysconfig/network/ifroute-mgmt-br
files:
- path: /etc/rancher/rancherd/config.yaml
permissions: 384
owner: 0
group: 0
content: |
server: https://$cluster-vip:443
role: agent
token: "ThisIsTheCorrectOne"
kubernetesVersion: v1.25.9+rke2r1
rancherVersion: v2.7.5
rancherInstallerImage: rancher/system-agent-installer-rancher:v2.7.5
labels:
- harvesterhci.io/managed=true
extraConfig:
disable:
- rke2-snapshot-controller
- rke2-snapshot-controller-crd
- rke2-snapshot-validation-webhook
encoding: ""
ownerstring: ""
To see what is the current cluster token value, log in your server node (i.e. with SSH)
and look in the file /etc/rancher/rancherd/config.yaml. For example,
you can run the following command to only display the token's value:
$ sudo yq eval .token /etc/rancher/rancherd/config.yaml
Collecting troubleshooting information
Please include the following information in a bug report when reporting a failed installation:
A failed installation screenshot.
System information and logs.
Available as of v1.0.2
Please follow the guide in Logging into the Harvester Installer (a live OS) to log in. And run the command to generate a tarball that contains troubleshooting information:
supportconfig -k -cThe command output messages contain the generated tarball path. For example the path is
/var/loq/scc_aaa_220520_1021 804d65d-c9ba-4c54-b12d-859631f892c5.txzin the following example: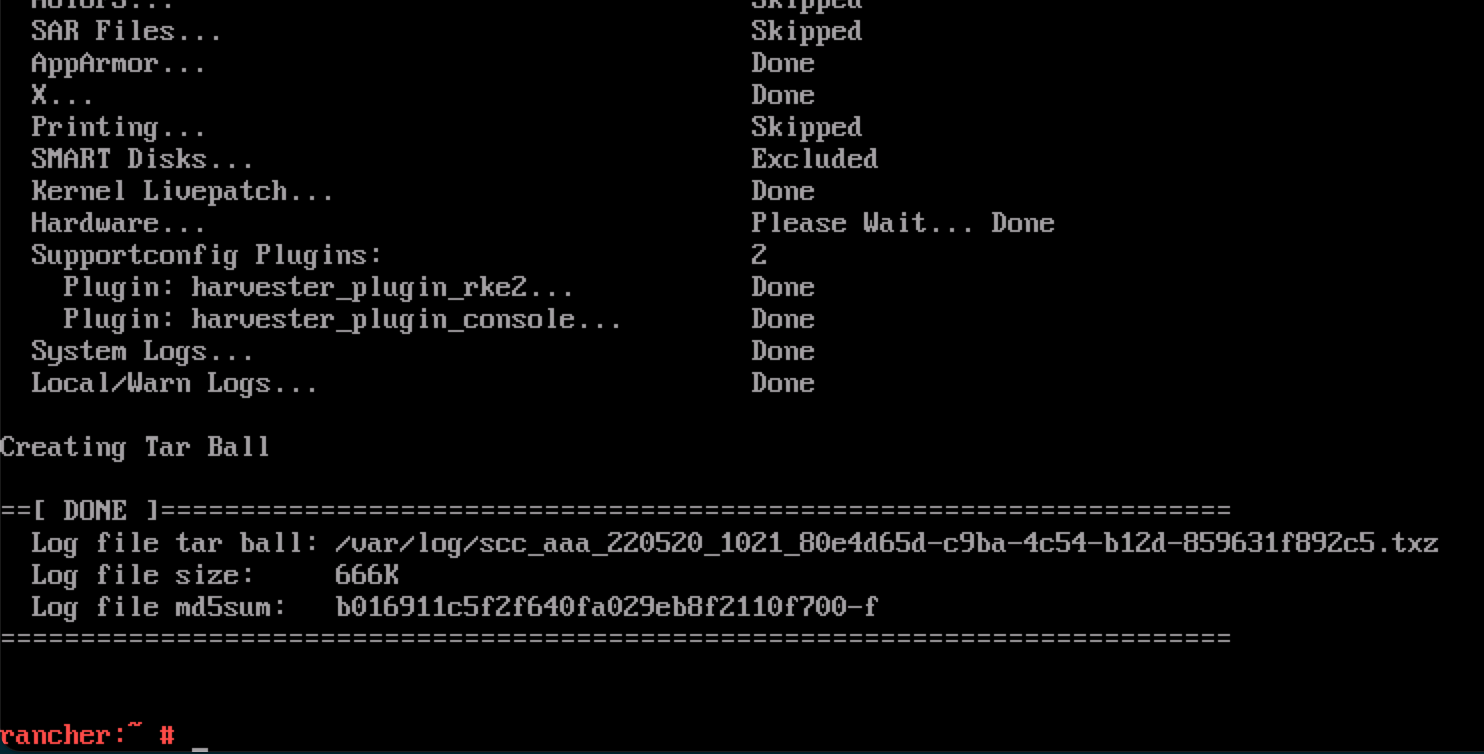 note
noteA failure PXE Boot installation automatically generates a tarball if the
install.debugfield is set totruein the Harvester configuration file.