Upgrade from v1.4.2/v1.4.3 to v1.5.0
General Information
An Upgrade button appears on the Dashboard screen whenever a new Harvester version that you can upgrade to becomes available. For more information, see Start an upgrade.
You can directly upgrade from v1.4.2 to v1.5.0 because Harvester allows a maximum of one minor version upgrade for underlying components. Harvester v1.4.2 and v1.4.3 use the same minor version of RKE2 (v1.31), while Harvester v1.5.0 uses the next minor version (v1.32).
For information about upgrading Harvester in air-gapped environments, see Prepare an air-gapped upgrade.
Update Harvester UI Extension on Rancher v2.11.0
You must use v1.5.0 of the Harvester UI Extension to import Harvester v1.5.0 clusters on Rancher v2.11.0.
-
On the Rancher UI, go to local > Apps > Repositories.
-
Locate the repository named harvester, and then select ⋮ > Refresh.
-
Go to the Extensions screen.
-
Locate the extension named Harvester, and then click Update.
-
Select version 1.5.0, and then click Update.
-
Allow some time for the extension to be updated, and then refresh the screen.
Known Issues
1. Management URL Status is "NotReady" During Upgrade
The Harvester console on some nodes may display Status: NotReady while the upgrade is in progress.
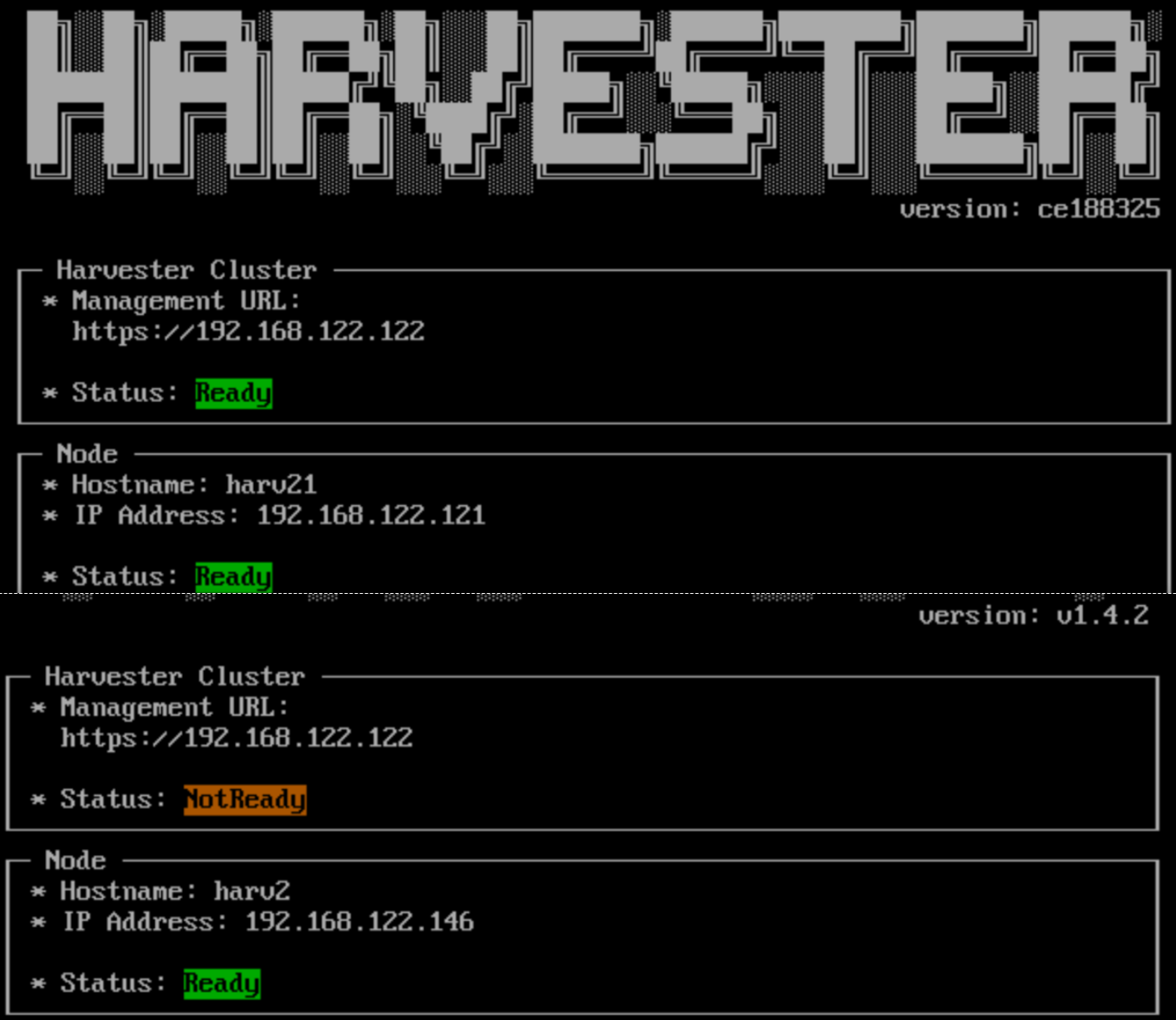
The correct status is displayed after the upgrade to v1.5.0 is completed.
Related issue: #7963
2. Air-gapped Upgrade Stuck with ImagePullBackOff Error in Fluentd and Fluent Bit Pods
The upgrade may become stuck at the very beginning of the process, as indicated by 0% progress and items marked Pending in the Upgrade dialog of the Harvester UI.
![]()
Specifically, Fluentd and Fluent Bit pods may become stuck in the ImagePullBackOff status. To check the status of the pods, run the following commands:
$ kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true
NAME AGE
hvst-upgrade-x2hz8 7m14s
$ kubectl -n harvester-system get upgradelogs -l harvesterhci.io/upgrade=hvst-upgrade-x2hz8
NAME UPGRADE
hvst-upgrade-x2hz8-upgradelog hvst-upgrade-x2hz8
$ kubectl -n harvester-system get pods -l harvesterhci.io/upgradeLog=hvst-upgrade-x2hz8-upgradelog
NAME READY STATUS RESTARTS AGE
hvst-upgrade-x2hz8-upgradelog-downloader-6cdb864dd9-6bw98 1/1 Running 0 7m7s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-2nq7q 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-697wf 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-kd8kl 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentd-0 0/2 ImagePullBackOff 0 7m42s
This occurs because the following container images are neither preloaded in the cluster nodes nor pulled from the internet:
ghcr.io/kube-logging/fluentd:v1.15-ruby3ghcr.io/kube-logging/config-reloader:v0.0.5fluent/fluent-bit:2.1.8
To fix the issue, perform any of the following actions:
-
Update the Logging CR to use the images that are already preloaded in the cluster nodes. To do this, run the following commands against the cluster:
# Get the Logging CR names
OPERATOR_LOGGING_NAME=$(kubectl get loggings -l app.kubernetes.io/name=rancher-logging -o jsonpath="{.items[0].metadata.name}")
INFRA_LOGGING_NAME=$(kubectl get loggings -l harvesterhci.io/upgradeLogComponent=infra -o jsonpath="{.items[0].metadata.name}")
# Gather image info from operator's Logging CR
FLUENTD_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.image.repository}")
FLUENTD_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.image.tag}")
FLUENTBIT_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentbit.image.repository}")
FLUENTBIT_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentbit.image.tag}")
CONFIG_RELOADER_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.configReloaderImage.repository}")
CONFIG_RELOADER_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.configReloaderImage.tag}")
# Patch the Logging CR
kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentbit/image\",\"value\":{\"repository\":\"$FLUENTBIT_IMAGE_REPO\",\"tag\":\"$FLUENTBIT_IMAGE_TAG\"}}]"
kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentd/image\",\"value\":{\"repository\":\"$FLUENTD_IMAGE_REPO\",\"tag\":\"$FLUENTD_IMAGE_TAG\"}}]"
kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentd/configReloaderImage\",\"value\":{\"repository\":\"$CONFIG_RELOADER_IMAGE_REPO\",\"tag\":\"$CONFIG_RELOADER_IMAGE_TAG\"}}]"The status of the Fluentd and Fluent Bit pods should change to
Runningin a moment and the upgrade process should continue after the Logging CR is updated. If the Fluentd pod is still in theImagePullBackOffstatus, try deleting it with the following command to force it to restart:UPGRADE_NAME=$(kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true -o jsonpath='{.items[0].metadata.name}')
UPGRADELOG_NAME=$(kubectl -n harvester-system get upgradelogs -l harvesterhci.io/upgrade=$UPGRADE_NAME -o jsonpath='{.items[0].metadata.name}')
kubectl -n harvester-system delete pods -l harvesterhci.io/upgradeLog=$UPGRADELOG_NAME,harvesterhci.io/upgradeLogComponent=aggregator -
On a computer with internet access, pull the required container images and then export them to a TAR file. Next, transfer the TAR file to the cluster nodes and then import the images by running the following commands on each node:
# Pull down the three container images
docker pull ghcr.io/kube-logging/fluentd:v1.15-ruby3
docker pull ghcr.io/kube-logging/config-reloader:v0.0.5
docker pull fluent/fluent-bit:2.1.8
# Export the images to a tar file
docker save \
ghcr.io/kube-logging/fluentd:v1.15-ruby3 \
ghcr.io/kube-logging/config-reloader:v0.0.5 \
fluent/fluent-bit:2.1.8 > upgradelog-images.tar
# After transferring the tar file to the cluster nodes, import the images (need to be run on each node)
ctr -n k8s.io images import upgradelog-images.tarThe upgrade process should continue after the images are preloaded.
-
(Not recommended) Restart the upgrade process with logging disabled. Ensure that the Enable Logging checkbox in the Upgrade dialog is not selected.
Related issue: #7955
3. Upgrade Stuck on Waiting for mcc-harvester Bundle CR
When you upgrade from an old Harvester version (such as v1.0.x, v1.1.x, and v1.2.x), the upgrade process may become stuck on waiting for the mcc-harvester bundle CR to become ready.
> kubectl get bundles -n fleet-local
NAME BUNDLEDEPLOYMENTS-READY STATUS
mcc-harvester 0/1 Modified(1) [Cluster fleet-local/local]; kubevirt.kubevirt.io harvester-system/kubevirt modified {"spec":{"configuration":{"vmStateStorageClass":"vmstate-persistence"}}}
The root cause is that the latest dependency_charts CRDs were not applied, which occurred because Helm does not manage CRDs for Harvester. To allow the upgrade to continue, run the following script:
kubectl apply -f https://raw.githubusercontent.com/harvester/harvester/refs/tags/v1.5.0/deploy/charts/harvester/dependency_charts/kubevirt-operator/crds/crd-kubevirt.yaml
kubectl apply -f https://raw.githubusercontent.com/harvester/harvester/refs/tags/v1.5.0/deploy/charts/harvester/dependency_charts/csi-snapshotter/crds/volumesnapshotclasses.yaml
kubectl apply -f https://raw.githubusercontent.com/harvester/harvester/refs/tags/v1.5.0/deploy/charts/harvester/dependency_charts/csi-snapshotter/crds/volumesnapshotcontents.yaml
kubectl apply -f https://raw.githubusercontent.com/harvester/harvester/refs/tags/v1.5.0/deploy/charts/harvester/dependency_charts/csi-snapshotter/crds/volumesnapshots.yaml
kubectl apply -f https://raw.githubusercontent.com/harvester/harvester/refs/tags/v1.5.0/deploy/charts/harvester/dependency_charts/whereabouts/crds/whereabouts.cni.cncf.io_ippools.yaml
kubectl apply -f https://raw.githubusercontent.com/harvester/harvester/refs/tags/v1.5.0/deploy/charts/harvester/dependency_charts/whereabouts/crds/whereabouts.cni.cncf.io_overlappingrangeipreservations.yaml
After five minutes, check the status in the mcc-harvester bundle CR of bundle.fleet.cattle.io/v1alpha1. If the same error is still displayed, you must resync the bundle CR using the following script:
#!/bin/bash
patch_fleet_bundle() {
local bundleName=$1
local generation=$(kubectl get -n fleet-local bundle ${bundleName} -o jsonpath='{.spec.forceSyncGeneration}')
local new_generation=$((generation+1))
patch_manifest="$(mktemp)"
cat > "$patch_manifest" <<EOF
{
"spec": {
"forceSyncGeneration": $new_generation
}
}
EOF
echo "patch bundle to new generation: $new_generation"
kubectl patch -n fleet-local bundle ${bundleName} --type=merge --patch-file $patch_manifest
rm -f $patch_manifest
}
for bundle in mcc-harvester
do
patch_fleet_bundle ${bundle}
done
You must also ensure that the cdi CRD exists.
> kubectl get bundle -n fleet-local
NAMESPACE NAME BUNDLEDEPLOYMENTS-READY STATUS
fleet-local mcc-harvester 0/1 Modified(1) [Cluster fleet-local/local]; cdi.cdi.kubevirt.io cdi missing
If the cdi CRD exists, run the patch_fleet_bundle script to resync the mcc-harvester bundle CR. Otherwise, run the following script to create the cdi CRD:
kubectl apply -f https://raw.githubusercontent.com/harvester/harvester/refs/tags/v1.5.0/deploy/charts/harvester/dependency_charts/cdi/crds/cdi.yaml
Related issue: #8163
4. Virtual Machines That Use Migratable RWX Volumes Restart Unexpectedly
A Longhorn issue causes virtual machines that use migratable RWX volumes to restart unexpectedly when the CSI plugin pods are restarted. This issue affects Harvester v1.4.x, v1.5.0, and v1.5.1.
The workaround is to disable the setting Automatically Delete Workload Pod When The Volume Is Detached Unexpectedly on the Longhorn UI before starting the upgrade. You must enable the setting again once the upgrade is completed.
The issue will be fixed in Longhorn v1.8.3, v1.9.1, and later versions. Harvester v1.6.0 will include Longhorn v1.9.1.