Upgrade from v1.0.0 to v1.0.1
This document describes how to upgrade from Harvester v1.0.0 to v1.0.1.
Note we are still working towards zero-downtime upgrade, due to some known issues please follow the steps below before you upgrade your Harvester cluster:
- Before you upgrade your Harvester cluster, we highly recommend:
- Shutting down all your VMs (Harvester GUI -> Virtual Machines -> Select VMs -> Actions -> Stop).
- Back up your VMs.
- Do not operate the cluster during an upgrade. For example, creating new VMs, uploading new images, etc.
- Make sure your hardware meets the preferred hardware requirements. This is due to there will be intermediate resources consumed by an upgrade.
- Make sure each node has at least 25 GB of free space (
df -h /usr/local/).
Make sure all nodes' times are in sync. Using an NTP server to synchronize time is recommended. If an NTP server is not configured during the installation, you can manually add an NTP server on each node:
$ sudo -i
# Add time servers
$ vim /etc/systemd/timesyncd.conf
[ntp]
NTP=0.pool.ntp.org
# Enable and start the systemd-timesyncd
$ timedatectl set-ntp true
# Check status
$ timedatectl status
- NICs that connect to a PCI bridge might be renamed after an upgrade. Please check the knowledge base article for further information.
Create a version
Log in to one of your server nodes.
Become root and create a version:
rancher@node1:~> sudo -i
node1:~ # kubectl create -f https://releases.rancher.com/harvester/v1.0.1/version.yaml
version.harvesterhci.io/1.0.1 created
By default, the ISO image is downloaded from the Harvester release server. To speed up the upgrade and make the upgrade progress smoother, the user can also download the ISO file to a local HTTP server first and substitute the isoURL value in the version.yaml manifest.
e.g.,
# Download the ISO from release server first, assume it's store in http://10.10.0.1/harvester.iso
$ sudo -i
$ curl -fL https://releases.rancher.com/harvester/v1.0.1/version.yaml -o version.yaml
$ vim version.yaml
apiVersion: harvesterhci.io/v1beta1
kind: Version
metadata:
name: v1.0.1
namespace: harvester-system
spec:
isoChecksum: <SHA-512 checksum of the ISO>
isoURL: http://10.10.0.1/harvester.iso
releaseDate: '20220408'
Start the upgrade
Make sure to read the Warning paragraph at the top of this document first.
Navigate to Harvester GUI and click the upgrade button on the Dashboard page.
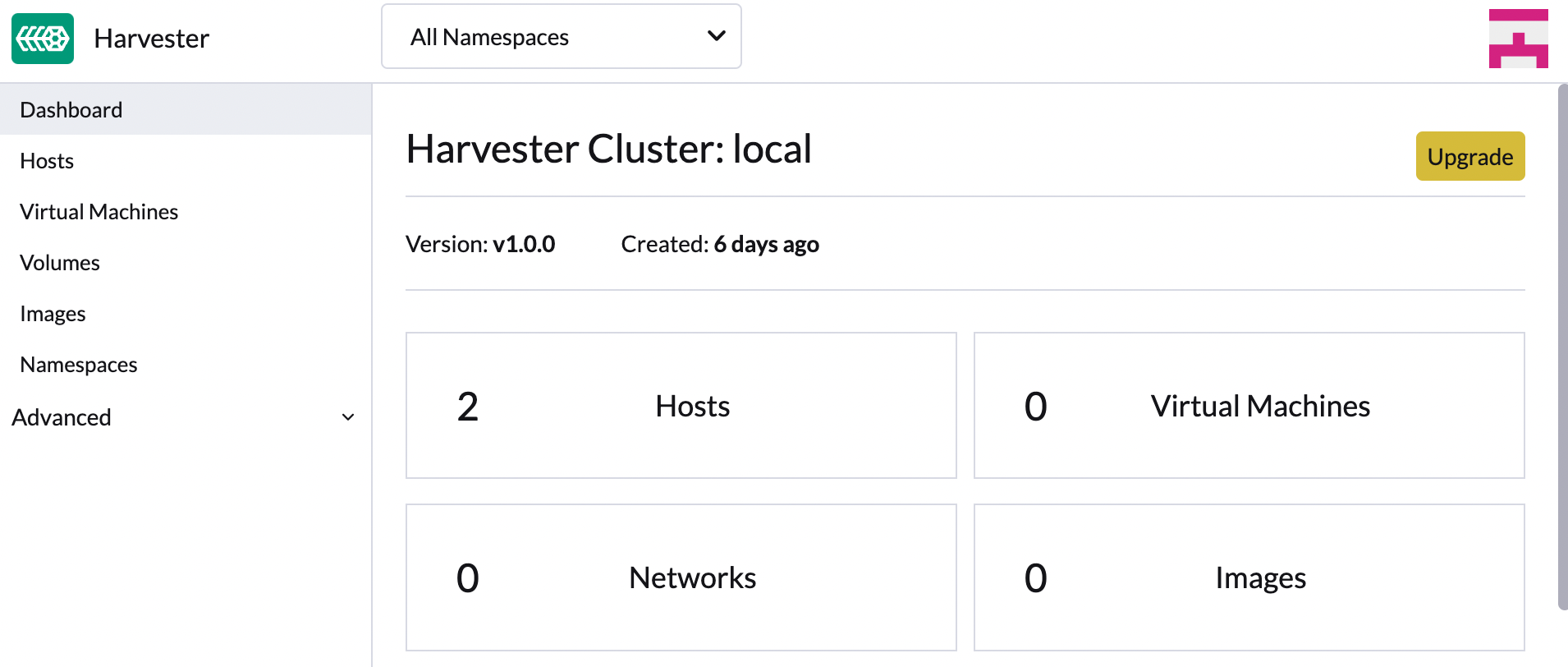
Select a version to start upgrading.
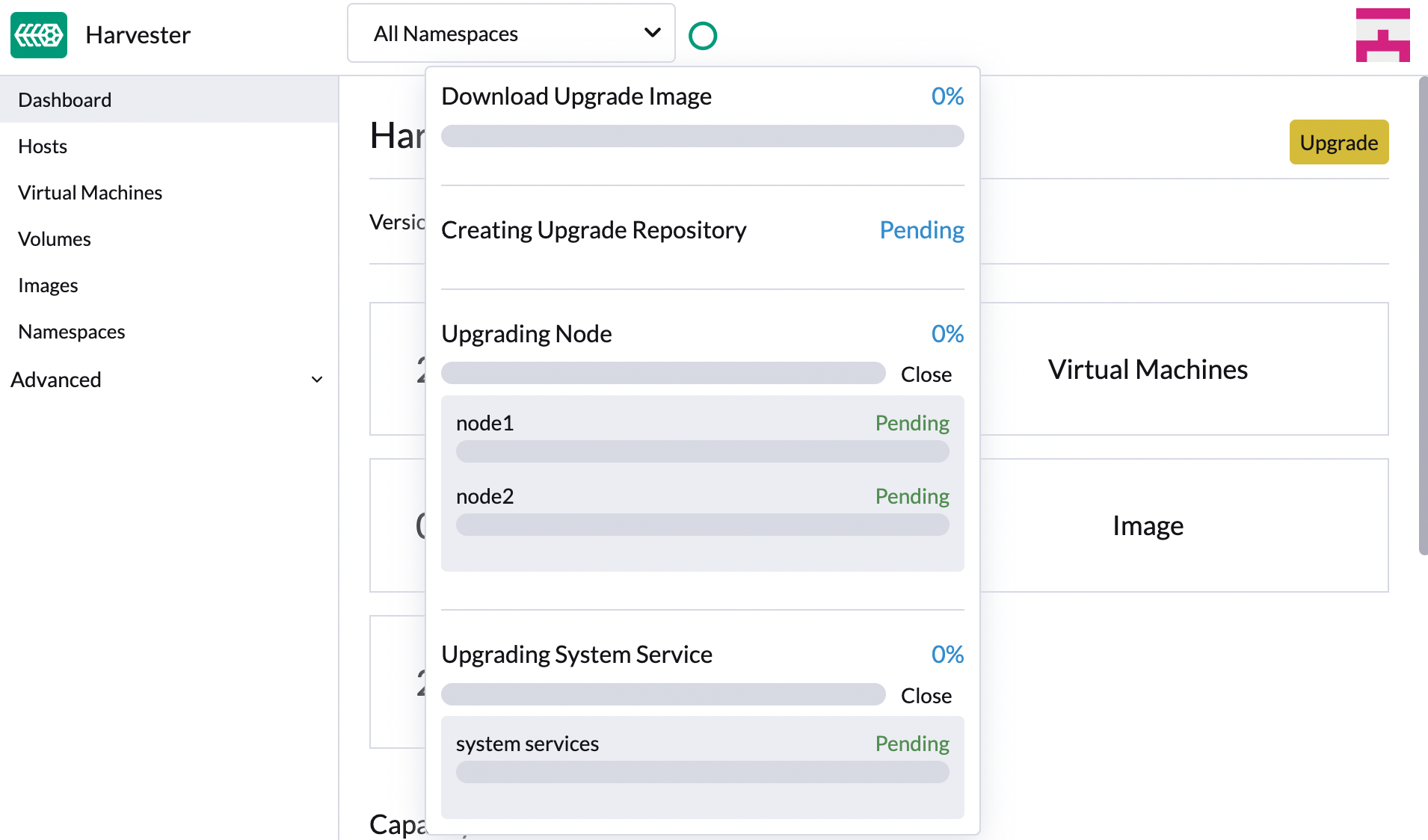
Click the circle on the top to display the upgrade progress.
Known issues
Fail to download upgrade image
Description
Downloading the upgrade image can't complete.
Workaround
We can delete the current upgrade and start over.
# log in to one of the server nodes
$ sudo -i
# list current upgrade, the name changes between deployments
$ kubectl get upgrades.harvesterhci.io -n harvester-system
NAMESPACE NAME AGE
harvester-system hvst-upgrade-77cks 119m
$ kubectl delete upgrades.harvesterhci.io hvst-upgrade-77cks -n harvester-systemWe recommend mirroring the ISO file to a local webserver, please check the notes in the previous section.
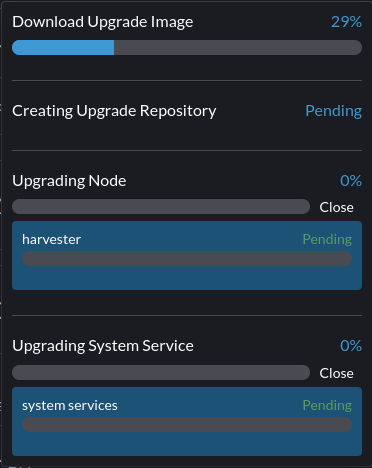
Stuck in Upgrading System Service
Description
The upgrade is stuck at Upgrading System service.
Similar logs are found in rancher pods:
[ERROR] available chart version (100.0.2+up0.3.8) for fleet is less than the min version (100.0.3+up0.3.9-rc1)
[ERROR] Failed to find system chart fleet will try again in 5 seconds: no chart name found
Workaround
Delete rancher cluster repositories and restart rancher pods.
# login to a server node and become root first
kubectl delete clusterrepos.catalog.cattle.io rancher-charts
kubectl delete clusterrepos.catalog.cattle.io rancher-rke2-charts
kubectl delete clusterrepos.catalog.cattle.io rancher-partner-charts
kubectl delete settings.management.cattle.io chart-default-branch
kubectl rollout restart deployment rancher -n cattle-systemRelated issues
VMs fail to migrate
Description
- A node keeps waiting in
Pre-drainingstate. - There are VMs on that node (checking for
virt-launcher-xxxpods) and they can't be live-migrated out of the node.
- A node keeps waiting in
Workaround
Shutdown the VMs, you can do this by:
- Using the GUI.
- Using the
virtctlcommand.
Related issues
fleet-local/local: another operation (install/upgrade/rollback) is in progress
Description
You see bundles have
fleet-local/local: another operation (install/upgrade/rollback) is in progressstatus in the output:kubectl get bundles -ARelated issues
Single node upgrade might fail if node name is too long (>24 characters)
- Related issues