Upgrade from v1.1.1/v1.1.2 to v1.1.3
General information
An Upgrade button appears on the Dashboard screen whenever a new Harvester version that you can upgrade to becomes available. For more information, see Start an upgrade.
For air-gapped environments, see Prepare an air-gapped upgrade.
Known Issues
1. The upgrade process is stuck when pre-draining a node. (Case 1)
Starting from v1.1.0, Harvester waits for all volumes to become healthy before upgrading a node (for clusters with three or more nodes).
When this issue occurs, you can check the health of the affected volumes on the embedded Longhorn UI. You can also check the pre-drain job logs. For more troubleshooting information, see Phase 4: Upgrade nodes.
2. The upgrade process is stuck when pre-draining a node. (Case 2)
An upgrade is stuck, as shown in the screenshot below:

Harvester is unable to proceed with the upgrade and the status of two or more nodes is SchedulingDisabled.
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
node1 Ready control-plane,etcd,master 20d v1.24.7+rke2r1
node2 Ready,SchedulingDisabled control-plane,etcd,master 20d v1.24.7+rke2r1
node3 Ready,SchedulingDisabled control-plane,etcd,master 20d v1.24.7+rke2r1
- Related issue:
- Workaround:
3. The upgrade process is stuck on the first node.
Harvester attempts to upgrade the first node but is unable to proceed. The upgrade eventually fails because the job is not completed by the expected end time.

- Related issue:
- Workaround:
4. The status of a Fleet bundle after the upgrade indicates that deployment errors occurred.
After an upgrade is completed, the status of a bundle managed by Fleet may be ErrApplied(1) [Cluster fleet-local/local: another operation (install/upgrade/rollback) is in progress]. The errors that occurred while deploying the bundle may block the next Harvester upgrade or managedChart update if not addressed.
To check the status of bundles, run the following command:
kubectl get bundles -A
The following output indicates that the issue exists in your cluster.
NAMESPACE NAME BUNDLEDEPLOYMENTS-READY STATUS
fleet-local fleet-agent-local 0/1 ErrApplied(1) [Cluster fleet-local/local: another operation (install/upgrade/rollback) is in progress]
fleet-local local-managed-system-agent 1/1
fleet-local mcc-harvester 1/1
fleet-local mcc-harvester-crd 1/1
fleet-local mcc-local-managed-system-upgrade-controller 1/1
fleet-local mcc-rancher-logging 1/1
fleet-local mcc-rancher-logging-crd 1/1
fleet-local mcc-rancher-monitoring 1/1
fleet-local mcc-rancher-monitoring-crd 1/1
- Related issue:
- Workaround:
5. The upgrade process stops after the upgrade repository is created.
Harvester is unable to retrieve the harvester-release.yaml file and proceed with the upgrade. The following error message is displayed: Get "http://upgrade-repo-hvst-upgrade-mldzx.harvester-system/harvester-iso/harvester-release.yaml": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
context deadline exceeded (Client.Timeout exceeded while awaiting headers)` message:
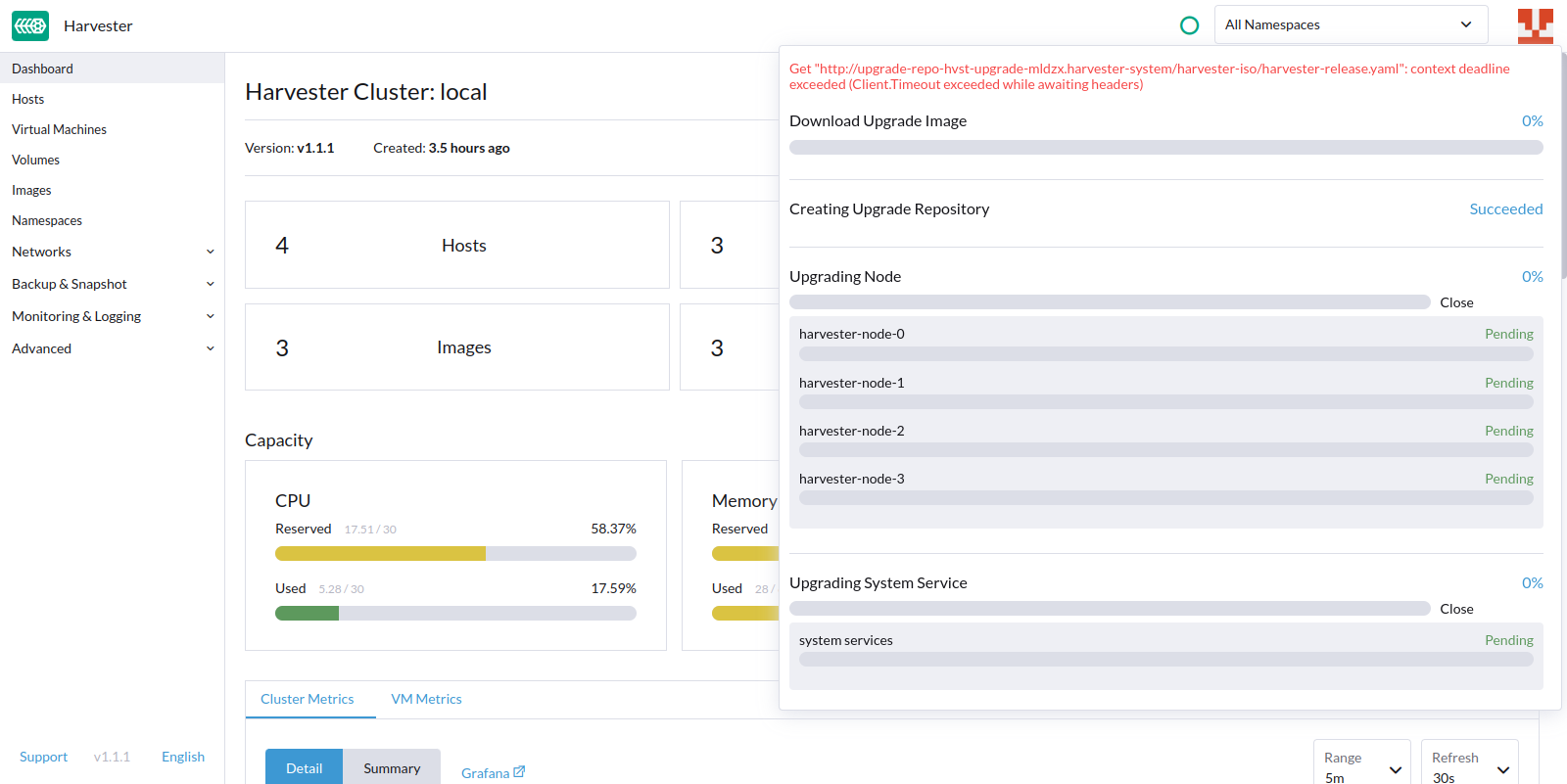
This issue was fixed in v1.1.2. For v1.1.0 and v1.1.1 users, however, the workaround is to restart the upgrade process.
- Related issue:
- Workaround:
6. The upgrade is stuck in the "Pre-drained" state.
This issue could be caused by a misconfigured pod disruption budget (PDB).
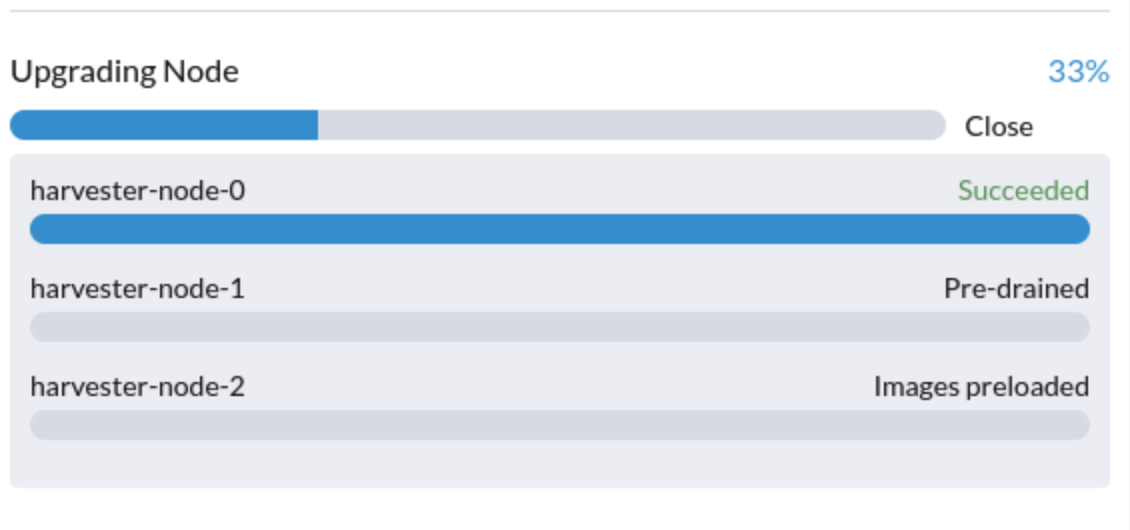
You can perform the following steps to confirm the cause and use the current workaround. In this example, the affected node is harvester-node-1.
Check the name of the
instance-manager-eorinstance-manager-rpod on the node.$ kubectl get pods -n longhorn-system --field-selector spec.nodeName=harvester-node-1 | grep instance-manager
instance-manager-r-d4ed2788 1/1 Running 0 3d8hThe output shows that the
instance-manager-r-d4ed2788pod is on the node.Check the Rancher logs and verify that the
instance-manager-eorinstance-manager-rpod cannot be drained.$ kubectl logs deployment/rancher -n cattle-system
...
2023-03-28T17:10:52.199575910Z 2023/03/28 17:10:52 [INFO] [planner] rkecluster fleet-local/local: waiting: draining etcd node(s) custom-4f8cb698b24a,custom-a0f714579def
2023-03-28T17:10:55.034453029Z evicting pod longhorn-system/instance-manager-r-d4ed2788
2023-03-28T17:10:55.080933607Z error when evicting pods/"instance-manager-r-d4ed2788" -n "longhorn-system" (will retry after 5s): Cannot evict pod as it would violate the pod's disruption budget.Check if a PDB is associated with the node.
$ kubectl get pdb -n longhorn-system -o yaml | yq '.items[] | select(.spec.selector.matchLabels."longhorn.io/node"=="harvester-node-1") | .metadata.name'
instance-manager-r-466e3c7fCheck the owner of the instance manager for the associated PDB.
$ kubectl get instancemanager instance-manager-r-466e3c7f -n longhorn-system -o yaml | yq -e '.spec.nodeID'
harvester-node-2If the output does not show the affected node, the issue exists in your cluster. In this example, the output shows
harvester-node-2instead ofharvester-node-1.Check the health of all volumes.
kubectl get volumes -n longhorn-system -o yaml | yq '.items[] | select(.status.state == "attached")| .status.robustness'The output should show that all volumes are marked
healthy. If not, consider uncordoning nodes to improve volume health.Remove the misconfigured PDB.
kubectl delete pdb instance-manager-r-466e3c7f -n longhorn-system