Upgrade from v1.1.0/v1.1.1 to v1.1.2
Please do not upgrade a running cluster to v1.1.2 if your machine has an Intel E810 NIC card. We saw some reports that the NIC card has a problem when added to a bonding device. Please check this issue for more info: https://github.com/harvester/harvester/issues/3860.
General information
Once there is an upgradable version, the Harvester GUI Dashboard page will show an upgrade button. For more details, please refer to start an upgrade.
For the air-gap env upgrade, please refer to prepare an air-gapped upgrade.
Known Issues
1. An upgrade is stuck when pre-draining a node
Starting from v1.1.0, Harvester will wait for all volumes to become healthy (when node count >= 3) before upgrading a node. Generally, you can check volumes' health if an upgrade is stuck in the "pre-draining" state.
Visit "Access Embedded Longhorn" to see how to access the embedded Longhorn GUI.
You can also check the pre-drain job logs. Please refer to Phase 4: Upgrade nodes in the troubleshooting guide.
2. An upgrade is stuck when pre-draining a node (case 2)
An upgrade is stuck, as shown in the screenshot below:

And you can also observe that multiple nodes' status is SchedulingDisabled.
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
node1 Ready control-plane,etcd,master 20d v1.24.7+rke2r1
node2 Ready,SchedulingDisabled control-plane,etcd,master 20d v1.24.7+rke2r1
node3 Ready,SchedulingDisabled control-plane,etcd,master 20d v1.24.7+rke2r1
- Related issue:
- Workaround:
3. An upgrade is stuck in upgrading the first node: Job was active longer than the specified deadline
An upgrade fails, as shown in the screenshot below:

- Related issue:
- Workaround:
4. After an upgrade, a fleet bundle's status is ErrApplied(1) [Cluster fleet-local/local: another operation (install/upgrade/rollback) is in progress]
There is a chance fleet-managed bundle's status is ErrApplied(1) [Cluster fleet-local/local: another operation (install/upgrade/rollback) is in progress] after an upgrade. To check if this happened, run the following command:
kubectl get bundles -A
If you see the following output, it's possible that your cluster has hit the issue:
NAMESPACE NAME BUNDLEDEPLOYMENTS-READY STATUS
fleet-local fleet-agent-local 0/1 ErrApplied(1) [Cluster fleet-local/local: another operation (install/upgrade/rollback) is in progress]
fleet-local local-managed-system-agent 1/1
fleet-local mcc-harvester 1/1
fleet-local mcc-harvester-crd 1/1
fleet-local mcc-local-managed-system-upgrade-controller 1/1
fleet-local mcc-rancher-logging 1/1
fleet-local mcc-rancher-logging-crd 1/1
fleet-local mcc-rancher-monitoring 1/1
fleet-local mcc-rancher-monitoring-crd 1/1
- Related issue:
- Workaround:
5. An upgrade stops because it can't retrieve the harvester-release.yaml file
An upgrade is stopped with the Get "http://upgrade-repo-hvst-upgrade-mldzx.harvester-system/harvester-iso/harvester-release.yaml":
context deadline exceeded (Client.Timeout exceeded while awaiting headers) message:
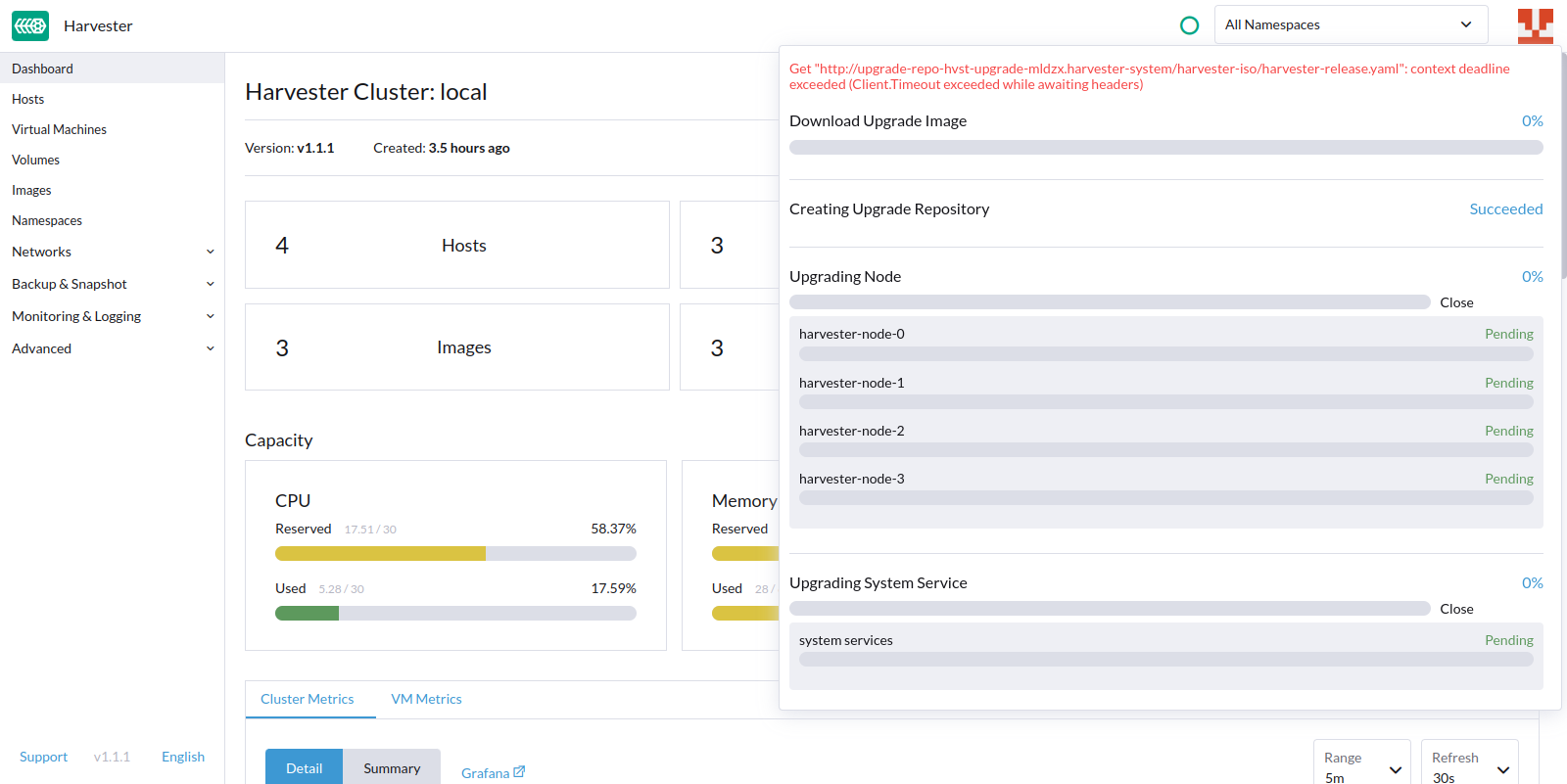
We have fixed this issue in v1.1.2. But for v1.1.0 and v1.1.1 users, the workaround is to start over an upgrade. Please refer to Start over an upgrade.
- Related issue:
- Workaround:
6. An upgrade is stuck in the Pre-drained state
You might see an upgrade is stuck in the "pre-drained" state:
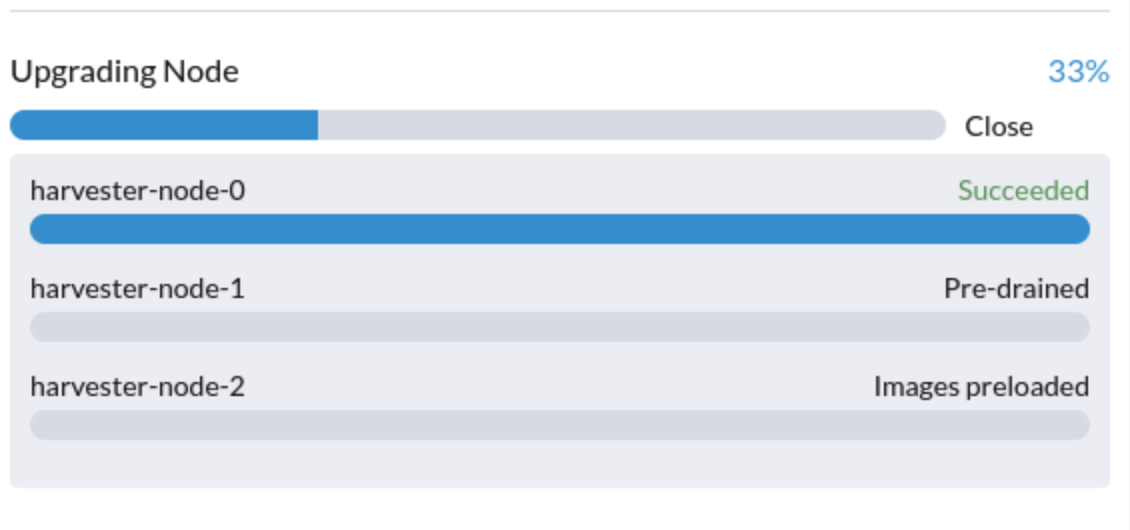
This could be caused by a misconfigured PDB. To check if that's the case, perform the following steps:
Assume the stuck node is
harvester-node-1.Check the
instance-manager-eorinstance-manager-rpod names on the stuck node:$ kubectl get pods -n longhorn-system --field-selector spec.nodeName=harvester-node-1 | grep instance-manager
instance-manager-r-d4ed2788 1/1 Running 0 3d8hThe output above shows that the
instance-manager-r-d4ed2788pod is on the node.Check Rancher logs and verify that the
instance-manager-eorinstance-manager-rpod can't be drained:$ kubectl logs deployment/rancher -n cattle-system
...
2023-03-28T17:10:52.199575910Z 2023/03/28 17:10:52 [INFO] [planner] rkecluster fleet-local/local: waiting: draining etcd node(s) custom-4f8cb698b24a,custom-a0f714579def
2023-03-28T17:10:55.034453029Z evicting pod longhorn-system/instance-manager-r-d4ed2788
2023-03-28T17:10:55.080933607Z error when evicting pods/"instance-manager-r-d4ed2788" -n "longhorn-system" (will retry after 5s): Cannot evict pod as it would violate the pod's disruption budget.Run the command to check if there is a PDB associated with the stuck node:
$ kubectl get pdb -n longhorn-system -o yaml | yq '.items[] | select(.spec.selector.matchLabels."longhorn.io/node"=="harvester-node-1") | .metadata.name'
instance-manager-r-466e3c7fCheck the owner of the instance manager to this PDB:
$ kubectl get instancemanager instance-manager-r-466e3c7f -n longhorn-system -o yaml | yq -e '.spec.nodeID'
harvester-node-2If the output doesn't match the stuck node (in this example output,
harvester-node-2doesn't match the stuck nodeharvester-node-1), then we can conclude this issue happens.Before applying the workaround, check if all volumes are healthy:
kubectl get volumes -n longhorn-system -o yaml | yq '.items[] | select(.status.state == "attached")| .status.robustness'The output should all be
healthy. If this is not the case, you might want to uncordon nodes to make the volume healthy again.Remove the misconfigured PDB:
kubectl delete pdb instance-manager-r-466e3c7f -n longhorn-system