Upgrade from v1.4.1 to v1.4.2
General Information
An Upgrade button appears on the Dashboard screen whenever a new Harvester version that you can upgrade to becomes available. For more information, see Start an upgrade.
For air-gapped environments, see Prepare an air-gapped upgrade.
Update Harvester UI Extension on Rancher v2.10.1
To import Harvester v1.4.2 clusters on Rancher v2.10.1, you must use v1.0.3 of the Rancher UI extension for Harvester.
-
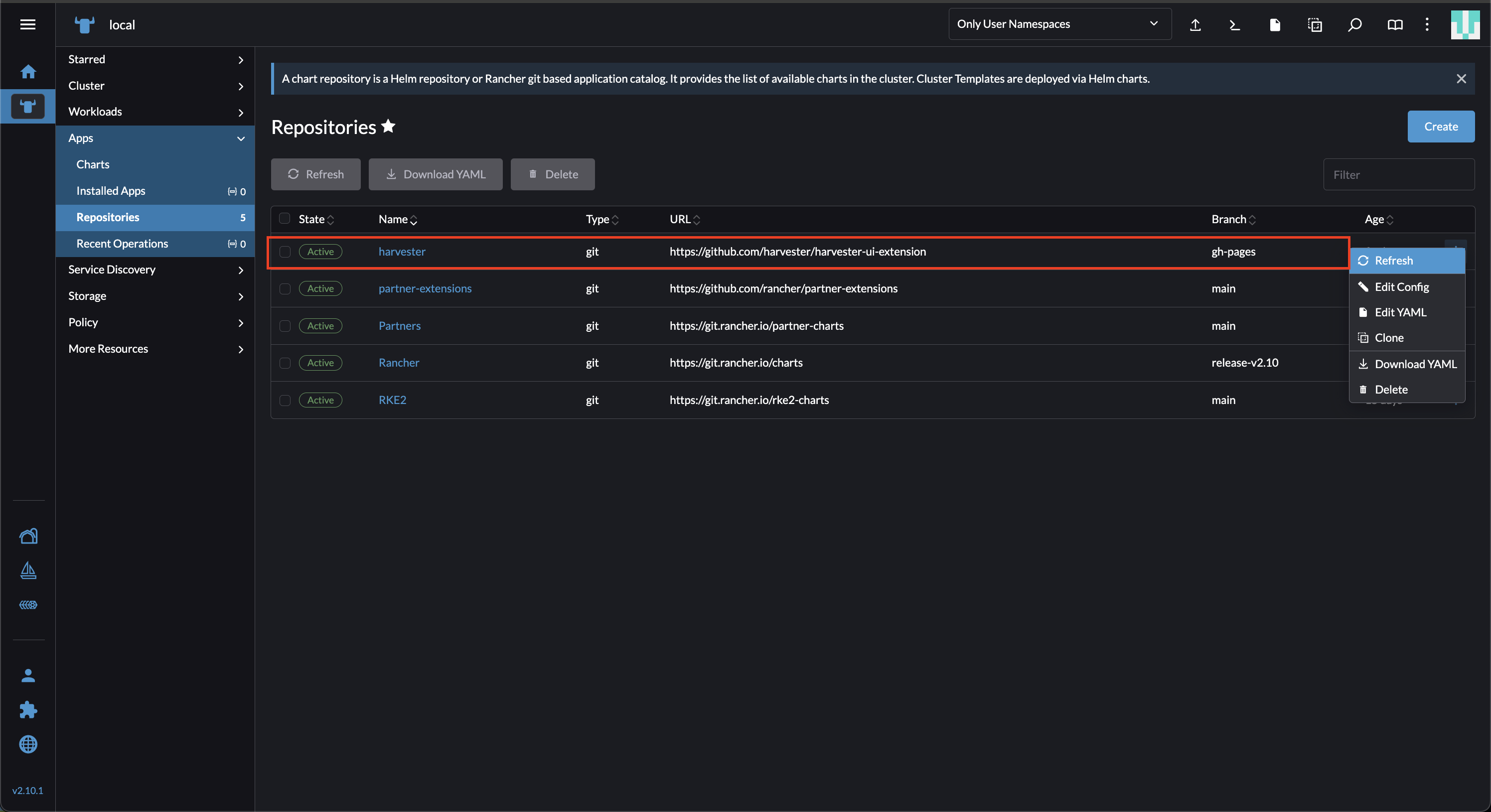
On the Rancher UI, go to local > Apps > Repositories.
-
Locate the repository named harvester, and then select ⋮ > Refresh. This repository has the following properties:
- URL: https://github.com/harvester/harvester-ui-extension
- Branch: gh-pages
-
Go to the Extensions screen.
-
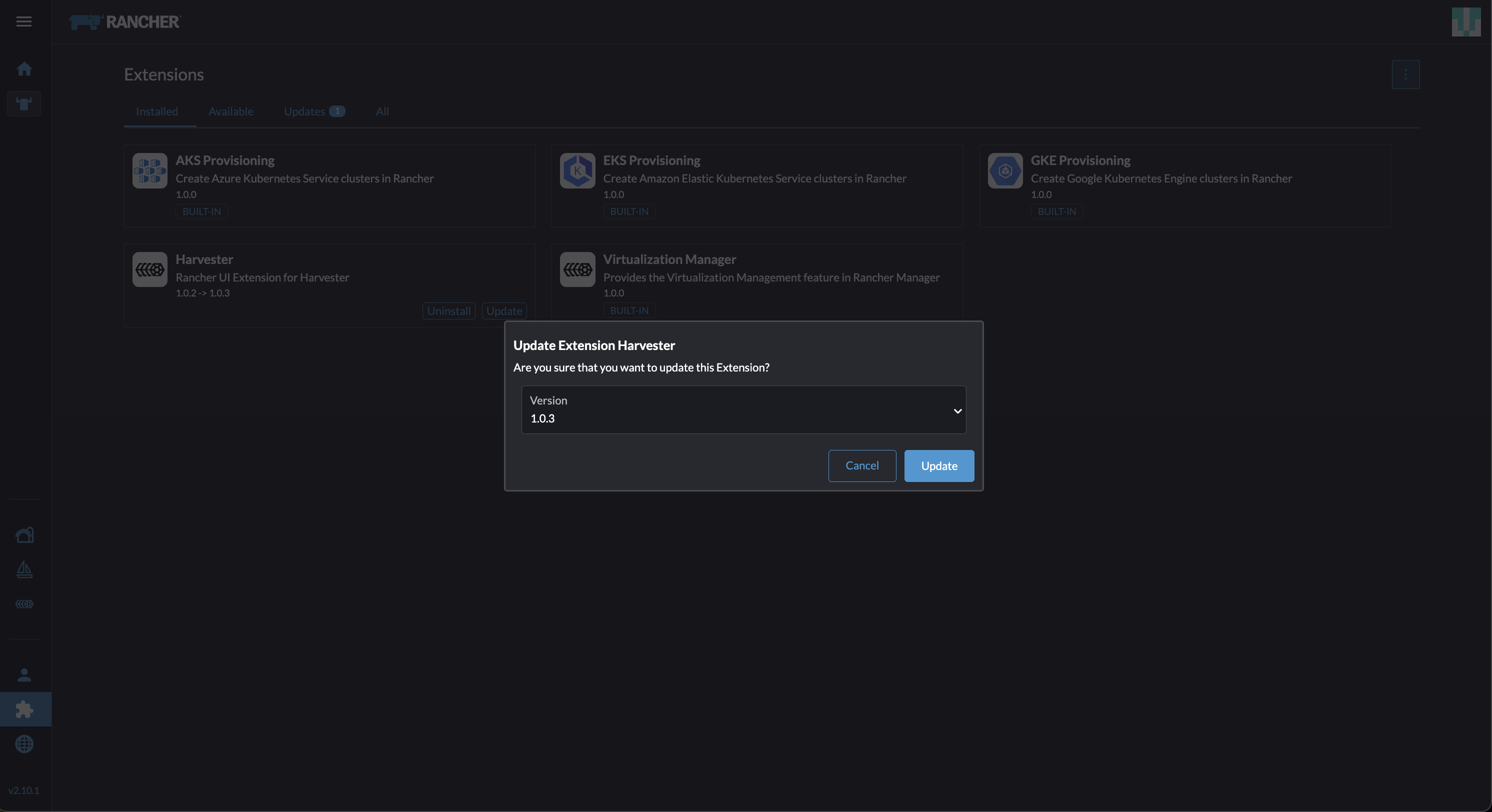
Locate the extension named Harvester, and then click Update.
-
Select version 1.0.3, and then click Update.
-
Allow some time for the extension to be updated, and then refresh the screen.
The Rancher UI displays an error message after the extension is updated. The error message disappears when you refresh the screen.
This issue, which exists in Rancher v2.10.0 and v2.10.1, will be fixed in v2.10.2.
Related issues: #7234 and #107
VM Backup Compatibility
In Harvester v1.4.2 and later versions, you may encounter certain limitations when creating and restoring backups that involve external storage.
Known Issues
1. High CPU Usage
High CPU usage may occur after an upgrade because of the backup-target setting's refreshIntervalInSeconds field, which was introduced in v1.4.2. If the field is left empty or is set to 0, Harvester constantly refreshes the backup target, resulting in high CPU usage.
To fix the issue, update the value of refreshIntervalInSeconds to a larger number (for example, 60) using the command kubectl edit setting backup-target. You can also update the value before starting the upgrade to prevent the issue from occurring.
Example:
value: '{"type":"nfs","endpoint":"nfs://longhorn-test-nfs-svc.default:/opt/backupstore", "refreshIntervalInSeconds": 60}'
Related issues: #7885
3. Upgrade Restarts Unexpectedly After "Dismiss it" Button is Clicked
When you use Rancher to upgrade Harvester, the Rancher UI displays a dialog with a button labeled "Dismiss it". Clicking this button may result in the following issues:
- The
statussection of theharvesterhci.io/v1beta1/upgradeCR is cleared, causing the loss of all important information about the upgrade. - The upgrade process starts over again unexpectedly.
This issue affects Rancher v2.10.x, which uses v1.0.2, v1.0.3, and v1.0.4 of the Harvester UI Extension. All Harvester UI versions are not affected. The issue will be fixed in Harvester UI Extension v1.0.5 and v1.5.0.
To avoid this issue, perform either of the following actions:
- Use the Harvester UI to upgrade Harvester. Clicking the "Dismiss it" button on the Harvester UI does not result in unexpected behavior.
- Instead of clicking the button on the Rancher UI, run the following command against the cluster:
kubectl -n harvester-system label upgrades -l harvesterhci.io/latestUpgrade=true harvesterhci.io/read-message=true
Related issue: #7791
4. Virtual Machines That Use Migratable RWX Volumes Restart Unexpectedly
A Longhorn issue causes virtual machines that use migratable RWX volumes to restart unexpectedly when the CSI plugin pods are restarted. This issue affects Harvester v1.4.x, v1.5.0, and v1.5.1.
The workaround is to disable the setting Automatically Delete Workload Pod When The Volume Is Detached Unexpectedly on the Longhorn UI before starting the upgrade. You must enable the setting again once the upgrade is completed.
The issue will be fixed in Longhorn v1.8.3, v1.9.1, and later versions. Harvester v1.6.0 will include Longhorn v1.9.1.